I often ask others engineers to describe to me what “good code” looks like. It’s also a pretty good interview question, as it gives the interviewer an idea of the types of things the candidate finds valuable in their work. In a way, it’s a measure of their coding craftsmanship — what they hold up as core tenets and how they will code review others on your team.
In their response, they will likely bring up the notion of “clean code” or “code that’s easy to read”. This is where I like to challenge them:
“What does clean code actually mean? What makes code easy to read?”
The answers you get can vary greatly based on the experience of the candidate, and it can be a decent way of distinguishing juniors from seniors There are many concepts that inevitably come up during this discussion: documentation, commenting, tests, functional vs. object oriented programming, composition vs. inheritance, linting, code styling, microservices vs. monoliths, file naming, directory structures, etc… Today, I want to focus on just one area of “clean code”. It’s a principle I think most engineers learn early in their careers — DRY code.
DRY
DRY¹ (“Don’t Repeat Yourself”) and is a simple principle — avoid code repetition in favour of abstractions or data normalization. I like the recent joke tweet from Kat Maddox to illustrate this:

Although this example is silly, I remember when I was first learning to code I had done something very similar to solve some rather basic problems. DRY is a good principle for junior engineers as it encourages critical thinking, and researching programming language features you may not already be familiar with. There is a lot of joy in being able to take 20 lines of code and reduce them to 1 or 2. It feels good, and it feels like you’ve created cleaner, simpler code. DRY becomes addictive and we carry the principle around with us in our toolbox deep into our careers.
As you write more production code and work on larger teams, I think DRY code starts to become too much of a blunt tool. In many cases DRY code is really awful and leads to code that’s difficult to maintain, difficult to test and difficult to read. It’s “so DRY it chafes²”! A good example of this is tests³. DRY code has absolutely no place in unit tests where the wrong abstraction (and I would argue any abstraction) will make your tests really difficult to read and could make failures difficult to track down. I’m a big fan of code that can be easily deleted. DRY code is often very difficult to delete without breaking something along the way. I see this sentiment is being felt more and more by others in the community.

DRY has its place. It’s great for API design, algorithms, event handling — to name a few areas. It’s also an important core principle when working at a bigger company. You probably don’t want every team to create the same thing multiple times, so establishing a pattern of code reuse across teams or between developers is important. So what are the cases where DRY fails us?
WET
Well… there’s WET⁴ (“Write Everything Twice”). The name is a bit tongue in cheek but it’s catchy. The principle isn’t to literally duplicate logic (like in the isEven example) but rather to use duplication in places where abstraction would actually be detrimental. I think there is some validity to having WET coding principles in your toolbox even when it results in you literally copy/pasting sections of code.
I think unit tests (again) are a great example where writing everything twice and then updating a single variable or a single argument is perfectly acceptable and even preferable. If a test becomes stale or out of date — it’s super easy to delete, and the performance penalty you pay for duplication is minimal.
WET is a useful paradigm to keep your back pocket purely as a solution to bad abstraction.
”Duplication is far cheaper than the wrong abstraction.”⁵ — Sandi Metz.
There’s also DAMP “Don’t Abstract Methods Prematurely” (as per Mat Ryer⁶). and AHA “Avoid Hasty Abstractions” (as per Kent C. Dodds⁷). I personally prefer to reserve the DAMP acronym for something else (see below) but the ideas proposed here are are the same. Rather than rushing to create a clever abstraction and look for a way to reduce code — just don’t even bother. Duplicate it. Use it in production for a while. Get other people to use it. Then refactor it only when a real problem surfaces.
I find engineers often end up creating problems for themselves that don’t exist yet. “But we have to build X. What if our users do Y and everything breaks?” What if they don’t? You might be wasting all your time building something nobody is going to use. Don’t get me wrong, it’s important to be able to anticipate concerns you might have with your code architecture and design systems that will survive for more than a few days, but there is such a thing as over-engineering and we have to be mindful of it. This is an art. It’s hard to predict what type of abstraction is too small, too big, or just right. I think having DRY embedded in our minds from early education tends to lead us to over-abstract and in general a bit of WETness is warranted.
DAMP
Then there’s DAMP “Descriptive And Meaningful Phrases” (as per Jay Fields⁸). Which is a bit different but also highly applicable. To me DAMP focuses less on the bad abstractions and more on code cleanliness and organization.
A good example to illustrate this is how Facebook names their 30,000 React components⁹.
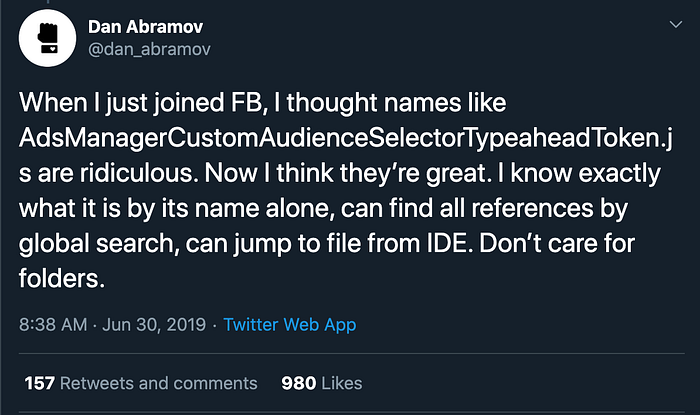
One side-effect of DRY thinking is that you tend to apply the same principle to other parts of the code: the way you name files, the way you name functions and variables, how you manage your directory structure, etc… I find this leads to problems as well. I found a few core principles of DAMPness useful:
- Don’t be afraid to write long detailed comments if you need to explain the “why” of your code¹⁰
- Don’t be afraid to use long descriptive names for files, functions, components, etc…
- Don’t be afraid to use long variable names (especially for constants)
- Don’t think about trying to make components reusable¹¹ and instead focus on making them easy to use and maintain
I agree with Dan Abramov when he says¹² we should stop obsessing about writing “clean code”. By the time you get to production and you have a bigger team — your code won’t be clean. Focus on making your code work (most important), easy to read, and easy to delete. You’ll always have the wrong abstraction, and even if you get it right — a new language, or paradigm, or framework, or platform will make your code completely obsolete in less than a decade. Try it yourself. Write some code you think is beautiful and clean, and set a reminder for yourself to take a look at it again in 2, 3, or 5 years time. I guarantee you will have a very different perspective.
Build something that will be easy to change — not something that will withstand the test of time.
- [1]: https://en.wikipedia.org/wiki/Don%27t_repeat_yourself
- [2]: https://www.youtube.com/watch?v=-NP_upexPFg&feature=youtu.be&t=1043
- [3]: https://stackoverflow.com/questions/6453235/what-does-damp-not-dry-mean-when-talking-about-unit-tests
- [4]: https://twitter.com/CodeWisdom/status/1198654768228511754
- [5]: https://www.sandimetz.com/blog/2016/1/20/the-wrong-abstraction
- [6]: https://twitter.com/matryer/status/1082278413510082560
- [7]: https://kentcdodds.com/blog/aha-programming#aha-
- [8]: http://blog.jayfields.com/2006/05/dry-code-damp-dsls.html
- [9]: https://www.reddit.com/r/reactjs/comments/6al7h2/facebook_has_30000_react_components_how_do_you/dhgruqh/
- [10]: https://mobile.twitter.com/EvHaus/status/1285954988242427908
- [11]: https://medium.com/the-non-traditional-developer/stop-writing-reusable-react-components-bd649cba2700
- [12]: https://overreacted.io/goodbye-clean-code/
